TCP总结
MSS
The maximum segment size is the largest “chunk” of data that TCP will send to the other end.
当连接建立起来后,每一端都能通知对端自己的MSS,让对面每次发送的Segment不要太大以至于被分片。An MSS option can only appear in a SYN segment.如果没有收到对面给的MSS信息,那么默认为536.(每个主机都必须能接受小于576的数据报)
我们可以知道的是,MSS的大小往往大一点是更好的,因为可以减少IP和TCP包头的开销。MSS往往设置为网卡出口的MTU-40。在发送数据时,我们不仅要考量对端的MSS,我们考虑网卡出口的MTU。我们选择合适的MSS是为了在避免分片的情况下尽量选择更大的一次性数据发送量,但是分片极有可能在路径中间的瓶颈处进行。也就是说双方提示给对面的MSS都很大,但是中间有个路由器不够争气。(解决这种情况的方法是使用path MTU discovery)
Half-Close
由于TCP是全双工的,双方都能发送接收数据,所以存在两条数据流,是否中断那条数据流是由发送方决定的。也就是说,A能关闭它作为发送方的数据流,但仍然可以选择在另一条数据流上读取数据。在关闭一条数据流后的状态就是处于Half-Close。注意,在使用Unix Api close关闭套接字,这不是进入半关闭状态,因为这会同时关闭读和写。
TCP State Transition Diagram
![]()
2MSL Wait State
如上图所示,TIME_WAIT也叫做2MSL状态。TCP的每种实现都必须设定一个值叫做maximum segment lifetime。它代表着一个Segment 被丢弃前在网络中能存在的最长时间。
TIME_WAIT存在处于两个目的:
- 我们假设客户端作为主动关闭方,那么客户最后发送的对Fin的Ack是可能会丢失的。但是这个信息对于服务器又是关键的,不收到它会以为你还在那边听,只是我的关闭信息没发过去。倘若客户没有进入TIME_WAIT状态,只会让服务端陷入无限的自责,一直以为是自己的问题。
- 在处于2MSL阶段时,这个连接的socket pair不能被重用,直到2MSL阶段结束。大多数的实现给了一个更严格的要求,处于TIME_WAIT的一端的Socket port都不能被重用,而不只是那对socket pair。在这个阶段收到的数据包都会被丢弃,等待2MSL可以让之前连接的数据包消失殆尽,不至于影响后续的连接。
疑问:为什么滞后的数据包只影响主动关闭方,不影响被动关闭方?
任何主动关闭方试图在关闭后立刻重启并绑定相同port的都会出问题。这个问题在客户端可能影响不大,但是对于服务器的影响确实巨大的。因为服务器的端口是众所周知的,试想需要等待1-4分钟才能重启服务器的影响(
我们可以给套接字加上SO_REUSEADDR选项,让其可以绑定处于TIME_WAIT阶段端口,但即使这样,如果我们试图连接相同的服务器,还是无法连接,因为那个socket对处于2MSL阶段。但是如果是服务器主动关闭,这却可以实现。:)
Half-Open
A TCP connection is said to be half-open if one end has closed or aborted the connection without the knowledge of the other end.
没有办法在半开状态传送数据,也没有办法察觉。常见的原因可能是突然断掉电源。
Simultaneous Open
TCP was purposely designed to handle simultaneous opens and the rule is that only one connection results from this, not two connections.
同时打开需要交换4条Segments,两端都扮演着客户端和服务端。
疑问:(这种同时打开的意义在哪?还有,是不是必须得创建监听套接字)
Delayed Acknowledgments
当TCP连接用于交互式数据传输时,每次传输的数据可能会很少。为了减少包头的开销以及减少链路上的数据包的数目,通过采取一种叫做延迟确认的技术。这种技术是说,在收到数据包后,不立即确认,而是先等待一阵子,看看有没有要发的数据,把数据和确认号一起发过去。大多数实现采用200ms的延迟。
TCP的计时往往是基于心跳的,它不是说一定得准确计时200ms后再发送。就好比一个闹钟,它每隔一段时间滴答一下,用以大致估计时间。闹钟的时间是在流逝的,但我不关注,我关注的只是心跳。比方说我关心200ms的心跳,那么我收到数据时可能离上次心跳刚过去0-199ms这都不能确定,所以我的延迟不是准确的200ms,而是到下一次的心跳发生的间隔。
Nagle Algorithm
这个算法意思是说不会有数据就传,而是等之前的数据的Ack确认号收到后再传,在此之前可以将数据收集起来。这个算法用于交互式的小数据传输,可以节省数据包头并且减少网络中包的数量。
这个算法是自适应的,Nagle算法是为了减少小的数据包的数量,降低网络中的通信压力,当信路通畅时,它发的也快,当信路状况不好时,它也可以通过减少包的数量,降低发送速率来缓解线路压力。
有时候我们需要关闭Nagle算法,比方说我们的信息交互是即时的,对延迟比较敏感。另外,假如我们键入指令让远程执行,如果TCP拿到一个字节数据发给服务端,服务端靠这一个字节的数据无法产生应答,直到Delayed(200ms)时间到了,才将Ack返回。这也就是说,至少要等200ms,才能让后续的字节发过去,造成了明显的延迟。
Sliding Windows
滑动窗口是为了控制两端的流量,在两端发送和接受速率存在很大差别时,不至于让大量的数据无意义的传输。
The window advertised by receiver is called the offered window.
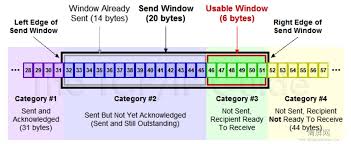
窗口移动有如下三种情况:
- 发送方的消息被确认时,发送窗口的左端右移。
- 当接受方的接收窗口数据被进程读取后,腾出空间,这时发送方的发送窗口右端右移。
- 发送窗口的右端左移(RFC是禁止的,但是TCP必须能与这样行为的对端成功合作)
窗口的大小往往是由进程确定的。
PUSH Flag
PUSH Flag是一个信号,用来告诉接受方,你把数据尽快递给进程,不要让数据在TCP的buffer里逗留等待额外的数据。接受方收到PUSH后,它就会知道,不需要等待额外的数据了。
现在往往没有Api去设置这个信号位,如果在数据发送后缓冲清空了的话,大多数伯克利衍生的实现会自动的加上这个标志。
Bulk Data Throughput(不太懂)
TCP重传
TCP的重传计时是以连接的RTT为基础的,而RTT又是随着时间会发生变动的,所以我们需要对RTT有一定的测量方案,并尽量反应网络状况。
第一个算法如下:
1 | R<-αR + (1-α)M |
其中α代表着平滑因子,一般选取0.9,而β一般选取2.RTO为计算得到的超时重传时间。
这个方法看上去不错,但是有一个问题,它无法反映RTT的急剧变化。比方说RTT突然增大,但是RTO不能反映这种剧烈变化,造成的影响是RTO比理论偏小,造成了不必要的重传。
Jacobson提出了另外的一种算法:
1 | Err = M - A |
g,h一般分别取0.125,0.25.
D便是测定的平均变化程度,这种算法便考虑了剧烈变化的影响。
关于RTT的测量需要注意一些问题
- 如果一个报文段准备发送时,而此时timer正在被使用,那么这个报文段不计入RTT的测量。
- RTT的计时是基于500ms-timer,也就是说550ms的发出到收到ACK时间间隔,可能被计入1tick或2ticks,分别代表500ms和1000ms。
- 重传的报文段不计入RTT的测量,因为不知道这个回应是针对哪个报文段。依据Karn’s Algorithm,我们将重新使用加倍后的RTO。
具体的例子参考《TCP/IP详解 Vol1》p304
拥塞避免
Slow Start
在发送方存在另外一个窗口,叫做拥塞窗口,用来模拟当前的网络状况。拥塞窗口初始值为一个Segment,每次收到一个ACK,拥塞窗口便增加一个Segment。每次发送方能够发送advertise window和拥塞窗口中的更小值量的数据。也就是说,我开始只能发一个Segment,但当我收到ACK后,我就能发两个了。当发送的两个都收到以后,我就能发四个。意思就是每收到一个ACK,就能让我能发送的个数增加1.
拥塞避免和Slow Start是不同的算法,当拥塞发生时,我们需要减缓发送速率,需要使用拥塞避免算法和Slow Start的结合。需要维护两个变量:
- 拥塞窗口(congestion window,cwnd)
- 慢启动门槛(slow start threshold size, ssthresh)
算法具体操作如下:
将cwnd初始化为1个Segment,ssthresh初始化为65535个字节。
TCP不会发送大于cwnd和advertised window中更小者的数据量。
当拥塞发生后(超时或连续收到3个相同的ACK),将ssthresh设置为当前窗口的一半(cwnd和advertised window的更小者,但至少是2个Segment),如果拥塞发生的原因是超时,那么cwnd设置为1个segment。
当新的数据被ACK后,我们需要增加cwnd,但增加的方式取决于我们在进行慢启动还是拥塞避免。
如果cwnd小于等于ssthresh,我们做慢启动,不然我们就是处于拥塞避免阶段。Slow Start到我们拥塞发生的地方,然后拥塞避免就开始了。
Slow Start的cwnd刚开始是1个Segment,每次收到收到一个ACK就会增加1.增长的速率是指数倍的,1,2,4…这也就是为什么拥塞发生时,ssthresh要减少至一半。拥塞避免阶段,每次收到一个ACK,增加1/cwnd。
我们在这里提到增长以段为单元,实际上是按照字节来的。
Fast Retransmit and Fast Recovery
有时不用等到超时我们就能判断丢包,当我们连续收到3个或以上相同的ACK,我们便可以知道极大可能是发生了丢包。这叫做快重传。另外,正如在上面提到的,不会开始慢启动,而是采取叫做快恢复的方式。之所以采用快恢复是因为我们注意到还是收到了3个ACK,说明当前的网络状况不算太糟糕。没必要启用慢启动。
算法的步骤大致如下:
当收到重复的ACK后,设置ssthresh为窗口的一半。(cwnd和advertised window的更小者,至少是2个Segment)
重传丢失的Segment,设置cwnd为ssthresh+3个Segment大小。
每次收到重复的ACK,将cwnd增加一个Segment大小,然后重传一个包。
当下一个对新数据的ACK到达后,将cwnd设置为ssthresh。
具体的计算实例参考《TCP/IP详解 Vol1》p314
TCP Persist Timer
假设我们有A,B双方通信,A准备给B发送消息,无奈B的接收窗口一直为0。后来B腾出了空间,将这个信息告诉A,可惜这个信息还丢了。因为这个信息不存在重传,所以导致了一个A想给B发信息发不了,B在等A信息的局面。
这时就需要使用使用Persist Timer,当A收到B的通告说接收窗口为0时,A会设置一个Persist Timer,一旦过了这个时间还没有B窗口能用的信息,它就怀疑是ACK丢了,于是它发送一个window probe,询问信息。如果ACK没丢,只是单纯的没地方,那么B的回复就重置Persist Timer,并且时间翻倍。
糊涂窗口症状
所谓的糊涂窗口症状是说,总是小的数据在传递,而不是一个满的数据段。
它的发生可能是两端的原因:接受方通告了太小的接收窗口(而不是等窗口大一点后再通告);或者发送方发送少量数据,而不是等到积累一定数据量后一起发。为避免糊涂窗口症状,两端都在为此付出努力。
- 接受方禁止通告小窗口,一般的算法是,等到可接收窗口的大小到了min(Segment,buffer space / 2)再做通告
- 发送方只有再满足如下条件才传输数据:
- Segment数据能够传送。
- 能传送对端advertise过的最大窗口的一半的数据。
- 我们能发送任何已有数据,要么我们开启了Nagle算法但不存在未确认数据了,要么禁止了Nagle算法。
这里就有可能发生一种情况,B给A通告的窗口大于一个Segment,A发送的数据为一个Segment,此时B的窗口不足以通告,但是必须通告,并且这个值不能为0,不然A的发送窗口就出现了右端左移的情况。
具体的例子参考《TCP/IP详解 Vol1》p329
TCP Keepalive Timer
通常设置keepalive选项的是服务器,为了判断当前是否是half open状态。
如果当前连接已经两个小时没有互动了,服务器就会发送一个Probe Segment到客户端,客户可能处于以下几种状态:
- 运行并可达,这时客户端会响应服务端,让它知道自己一切都好,然后服务端重新设置keepalive timer为2个小时。
- 宕机,服务器收不到回复,并且在75秒后超时。服务器一共会发10个,分隔75秒,如果一个回复都收不到,服务器都会猜测客户端已经宕机,随机关闭连接。
- 宕机又重启,这时客户端收到Probe,因为刚重启,会相应一个Reset,导致服务端终止连接。
- 运行不可达,这种情况类似第二种,TCP不能辨别。