JOS总结
操作系统的启动
BIOS
机器在启动时,首先运行BIOS,负责初始化中断向量,以及对设备进行检查。随后将boot loader程序加载到0x7c00处,boot loader在磁盘的第一个扇区。
Boot Loader
在加载进内存后,跳转到boot loader执行,boot loader主要负责对内核的引导。
在执行boot loader代码时,首先初始化一些寄存器,包括ds,es,ss等等,然后设置代码段选择子和数据段选择子,接着调用 lgdt gdtdesc加载全局描述符表,这时cpu还处于实模式状态,只能访问1MB以下的内存,这时boot loader需要开启保护模式以访问高地址内存,调用lcr0 开启保护模式。然后调转到 PROT_MODE_CSEG: protcseg执行。注意这时的PROT_MODE_CSEG为0,也就是说,内核的加载地址即是实际地址。
protcseg处的代码便是读入内核的ELF文件,将ELF头读入地址0处,根据ELF头,将相应内核段读入相应的地址。在加载完成后,跳转至e_entry执行内核代码。
需要牢记的是,在代码中的地址我们称之为虚拟地址或链接地址,在开启了保护模式后(设置cr0的低位为1),会经过全局描述符表项来生成线性地址,如果开启了分页(设置cr3的低位为1),则会将线性地址经过分页转换为物理地址,否则,线性地址就等于物理地址。
此时我们只是开启了保护模式,但是并没有开启分页。所以在内核的开始部分,第一件事就是开启分页,将初始的页目录加载进cr3,这个初始的页目录很简单,单纯的将[KERNBASE,KERNBASE+4MB]映射到[0,4MB],开启分页后,在访问地址时会经过CPU中MMU的转换,并会对权限进行检测。
到这里,boot loader工作就全部结束了,剩下的就是把控制权转交给内核,并对其他的操作系统组件进行初始化。
内存管理
这是我们目前的物理内存分布。
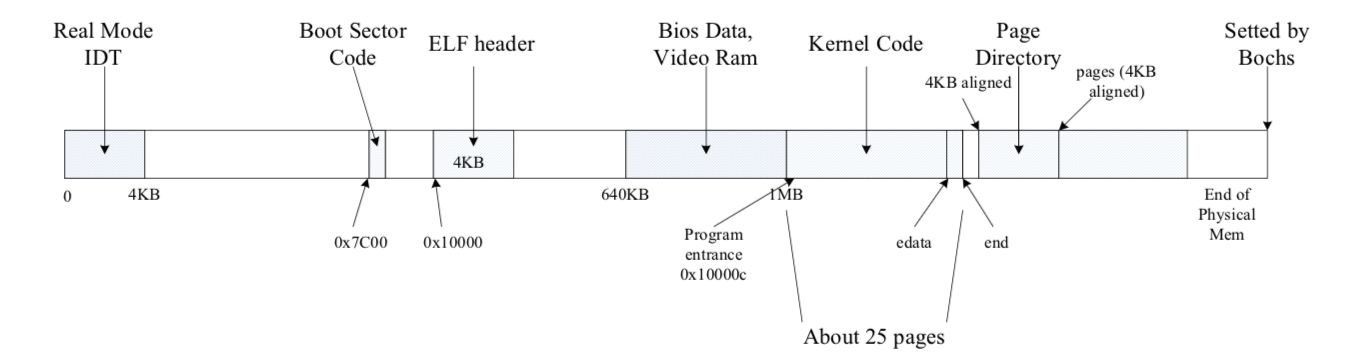
此时,我们的虚拟内存只是简单的映射了KERNBASE开始的4MB空间,我们需要对内存做更多的管理。
首先,不管虚拟内存怎样映射,我们首先需要对物理内存做管理,关于物理内存怎样分配,物理内存分配情况的记录等等。
JOS里面用struct PageInfo来记录物理页的分配情况
1 | struct PageInfo{ |
其中,pp_link记录着上一页可用页面的地址,pp_ref则记录着该物理页面被多少虚拟页映射。通过这个结构便可以很容易的维护物理页信息。分配时将空闲页从链表中剔除,释放时嵌入链表。
现在我们的虚拟内存表还过于简单,我们需要做更复杂的映射。
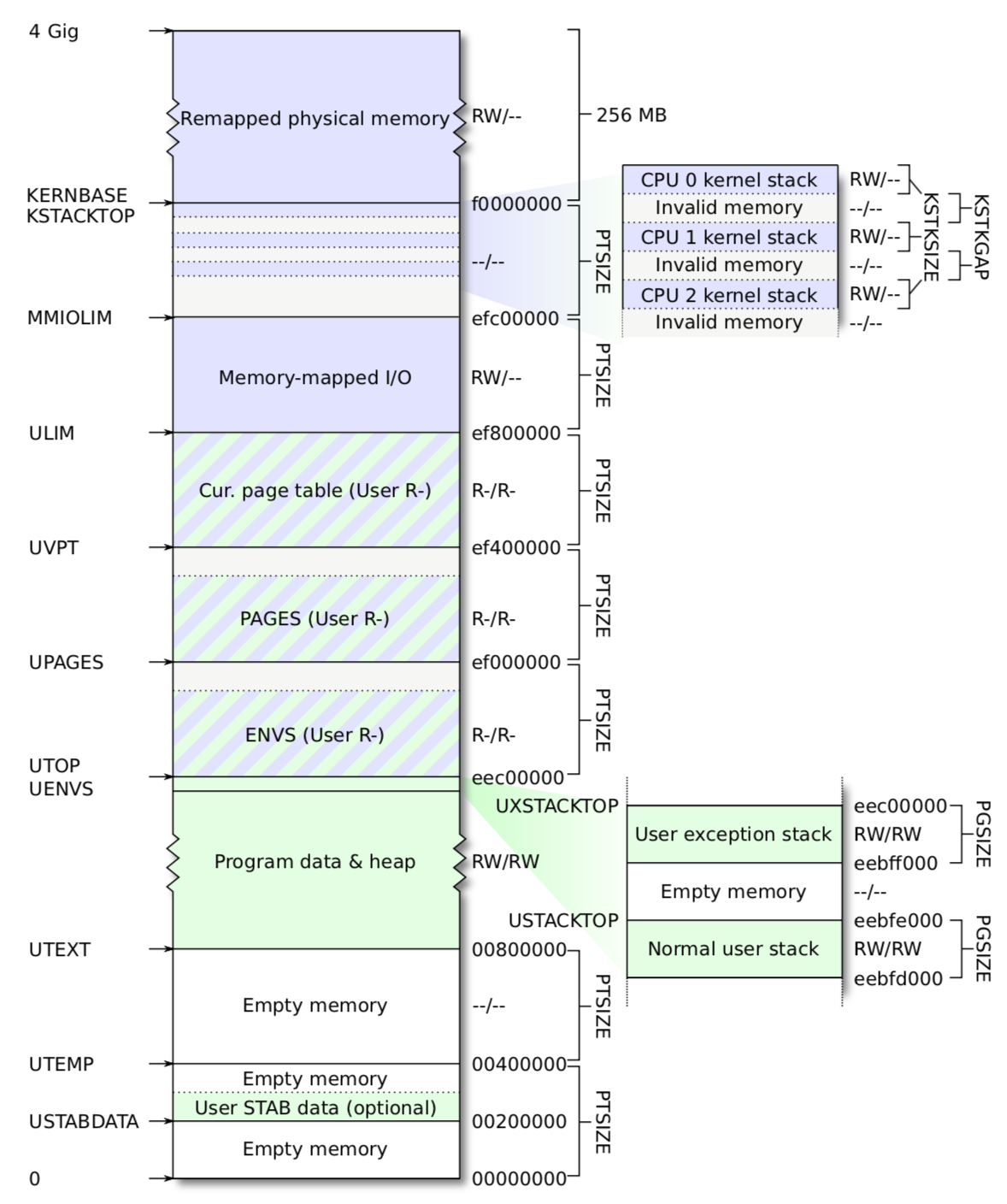
这是我们虚拟内存的布局,我们需要完成部分的映射。
首先是[UPAGES,UPAGES+PTSIZE]映射到我们的pages管理部分,也就是一系列PageInfo结构。
然后是映射[KERNTOP-KSTKSIZE,KSTACKTOP]到[bootstack,bootstack+32KB]处。
再然后将[KERNBASE,KERNBASE+256MB]映射到[0,256MB处],这样也覆盖了之前的简单映射部分(向后兼容?)
映射完后,将cr3寄存器的值换成新的目录表地址。
(疑问,bootstack具体地址?vupt映射)
进程管理
类似于struct PageInfo记录物理页信息,用Env来记录进程信息。
1 | struct Env { |
首先需要对PCB表进行内存分配,这个表的大小决定了进程的数目,表里存放的也是Env信息,这些信息都是由内核进行管理,所以访问权限是用户只读。
之前的gdt表里只有内核数据段和内核代码段(虽然基地址都是0),现在多了用户进程,需要为用户环境段分配相应的gdt描述符。于是多了用户数据段和用户代码段。然后加载新的描述符表。
(在jos里,段基地址都是0,只是权限不同)
这些初始化工作完成后,就可以正式创建进程了。
创建进程调用env_create函数,先调用env_alloc为进程分配Env结构并初始化相应信息,然后为进程创建页表,该页表拷贝kern_dir,将UVPT重新映射到自己的页表。env_tf表示进程运行时的寄存器信息,我们在创建进程时也需要初始化这些信息。初始化完成后,就可以等待调度了,因为运行时的一些必要信息已经准备好了。
调用env_run()运行进程,下面是env_run()的代码
1 | void |
env_pop_tf()将进程保存的环境复原,开始运行。
1 | void |
关于优先级
优先级有三种存在方式,分别是CPL、RPL、DPL。CPL是当前的优先级,由当前的cs段的最后三位体现。RPL是请求权限,在用户环境中,RPL和CPL相同。但是因为请求资源切换到内核环境,就会不一样。这是为了防止用户进程在通过内核请求资源时,访问到本不属于它的资源。DPL很好理解,就是某段的访问级别,存在于描述符中。
中断
到目前为止,我们都没有一个有效的办法来暂停一个进程,我们需要Unix中类似中断、trap等机制来实现异常的控制流。
中断和异常都是”保护控制机制”(PCT),它们将处理器从用户模式转移到内核模式。在CSAPP中叫做异常控制流,有4种,分别是中断、陷阱(trap)、异常、终止。其中中断是异步的,随时都可能发生,而其他的则是当前指令引发的。
trap执行完处理程序后,执行的是下一条指令,异常执行完处理程序后返回的是发生异常的指令。
中断描述表存储有中断向量和中断门描述符,中断描述表的地址存储在IDT寄存器中。当发生中断时,由IDT找到中断描述表,再根据中断向量作为索引找到中断门描述符,描述符中存有处理程序的选择子和DPL,再由处理程序的选择子在GDT中找到具体处理程序地址。
x86使用0-31号作为处理器内部的同步异常,像除零异常、缺页异常等。使用32号之上的中断号用于软件中断或硬件中断。
在中断跳转到中断处理程序前,我们需要保存运行环境,并且这部分不能被用户代码访问到。当遇到异常时,经过中断门后,特权级由用户级变为内核级,这个过程中会将用户栈切换为内核栈,内核栈的位置由TSS来存储,切换到内核栈后,会在内核栈中压入发生中断时的寄存器信息,像esp、ss、cs、eip、eflags等等,(如果中断处理程序需要,可能还要压入些额外信息,比如页异常需要压入error code。)然后将中断处理程序的cs、eip加载进寄存器中,开始运行处理程序。
(疑问:内核栈中压入的值是什么时候出栈的;内核态转变为用户态的时机)
内核栈中的值不见得弹出,下次直接被覆盖就好了
内核态在调用iret后转变为用户态
系统调用
用户特权级下,需要通过系统调用来访问内核资源。系统调用把参数存在通用寄存器里,然后通过int SYS_CALL软中断被中断处理程序处理,并成功进入内核环境。中断处理程序根据保存的寄存器信息提取出系统调用的参数,包括系统调用号,参数等等。并将返回值保存在待恢复寄存器信息中的eax中。
SMP
SMP指所有处理器都是平等的,包括内存平等和IO平等。虽然所有处理器都是平等的,但是可以分为BSP和AP,前者用于系统的boot过程以及初始化各个AP,至于哪个cpu是BSP的信息以及其他的关于SMP的配置信息都放在BIOS中。
每个cpu都有一个LAPIC单元,用于传递和相应中断,LAPIC为与它相连的cpu提供了唯一ID。我们只使用到了LAPIC的部分功能,读取LAPIC判断当前cpu ID;从BSP发送IPI给AP,用于初始化AP;用内置的计时器来支持抢占式多任务。
cpu访问它的LAPIC通过MMIO,有部分内存连线硬连接到LAPIC。我们将这部分物理地址映射到0xEF800000开始的4MB
AP启动流程
在启动AP前,BSP需要从BIOS中读取有关于多处理器的配置信息,比如说cpu的数目,LAPIC的MMIO地址等等。调用boot_aps()来初始化AP,AP以实模式启动,类似于boot过程,区别是我们的BSP可以控制AP执行代码的加载地址。在我们实验里,我们将其加载至0x7000处。
之后,boot_aps()向各个AP发送STARTUP IPIs来依次激活各个cpu,并为每个cpu指定了内核栈,cpu通过执行0x7000处的初始化代码完成初始化,包括启动保护模式,开启分页,加载gdt等等,并依次调用lapic_init(),env_init_percpu(),trap_init_percpu()完成初始化工作,完成后向BSP发送完成初始化的信号。
CPU初始化
- 内核栈。每个cpu都有一个内核栈,以保证互不干扰。
- TSS和TSS描述符。TSS用于保存内核栈DS、ESP,TSS的段选择子在cpus[i].cpu_ts中,通过段选择子在gdt中可找到TSS。
- 当前进程指针。每个cpu都保存着当前运行的进程Env
- 所有寄存器。寄存器在每个cpu上都有一份
内核锁
为了防止多CPU同时执行内核代码对内核数据产生影戏那个,我们必须保证每次只有一个cpu运行在内核环境。我们采用内核锁的方式,保证最多只有一个CPU处在内核状态。
调度
在多CPU环境配置好后,我们需要对进程进行调度,用户进程可以通过系统调用主动让出cpu,在释放进程时会进行调度,在进程调用ipc_recv时也会进行调度,在trap中,发现中断进程已经终止时也会进行调度。
Fork
我们现在有了基本的进程模型,还需要类似于Unix中的fork机制来完成更复杂的任务。我们可以先设计一个简单的fork模型,用户通过系统调用进入内核空间,内核通过拷贝进程的内存空间完成复制,并通过将子进程的tf->eax设置为0达到一次调用、两次返回的效果。
但是我们可以看到,对于父进程内存空间的复制,进行全部的拷贝,这是一种浪费,因为父子进程内存大部分都是相同的。考虑到这点,我们采用一种叫做写时复制的技术。
写时复制是说fork后,父子进程共享相同的物理内存,并给相应的虚拟页面写上COW标志,当某一方试图写共享页面时,就会触发页异常,调用相应的异常处理程序,将发生写异常的页面拷贝一份。
页面异常处理程序和中断过程有点区别,在发生页面异常后,先是触发异常中断,将寄存器值压入内核栈中,而后dispatch发现是页面中断,于是把压入内核栈的数据压入异常栈,并设置用户进程的eip为用户级的处理程序,继而调用env_run转变为用户级并运行页面处理程序,在处理完后,从异常栈中恢复寄存器的数据。也就是说真正的处理过程实际上是在用户环境执行的。
IPC
jos的IPC有几种,首先是基于系统调用sys_page_map,将进程A的页面映射到进程B的某页,实现页面的共享。还有一种是ipc_recv和ipc_try_send,ipc_recv系统调用告诉内核,我想收到数据,并且把数据放在哪个地址,然后就重新调度,等待其资源准备好。ipc_try_send系统调用向目标进程发送数据,如果目标进程没准备好收,返回错误信息。否则把数据送到目标进程,并且把目标进程设置为可运行。最后一种是文件系统中即将介绍的pipe,也是基于sys_page_map的原理。
文件系统
文件系统在磁盘上的存储有如下几个部分,超级块、位图、Inode、实际文件内容。其中超级块用于描述文件系统根目录的元信息,位图记录磁盘的分配情况,Inode是描述文件的元信息。但是jos里面没有将Inode和实际文件内容分开,而是将文件的元信息存在所在目录的目录项里。简化了很多。
jos的文件系统还有一个特别之处在于对于文件的管理是由一个特殊的进程来完成的,关于底层对磁盘的读写不用了解太多(主要是我也不懂),抽象出来就是,这个特殊的文件管理进程可以读出某一磁盘块的内容,它读出的内容映射在它自己的虚拟内存里面,从0x10000000~0xD0000000,正好3G,也就是说jos支持的最大磁盘也就是3G。
接下来介绍几个关键的数据结构
1 | struct File{ |
File用于记录文件的信息,算是基于磁盘块的一层抽象。通过它可以知道一个文件的基本信息,比如说文件名、大小、具体在哪几个块里。
我们可以把文件系统找文件的过程分为如下几步:
- 从Super块开始,根据目录名和待查询文件名的比对,一层层往下
- 找到期待的文件后,保存File信息,通过File就可以很容易读出文件对应的块了
1 | struct Fd{ |
Fd用于描述打开文件,文件对应的设备ID,当前的偏移量,打开方式,文件id等等。从普通进程的0xD0000000开始,有一段空间用于保存Fd,最多可达32个。
1 | struct OpenFile{ |
OpenFile将File和Fd联系起来,通过o_fileid可以得到OpenFile数组的下标,这个值保存在Fd的fd_file中。因此,当我们在普通用户程序中通过Fd读文件时,可以通过fd_file在文件管理进程中找到对应的OpenFile结构,然后通过OpenFile里的File结构完成实际文件操作。
在普通进程和文件管理进程中各有一个fsipc结构,用于传递打开文件的信息。
我们来看看具体的流程
打开文件
1 | Regular env FS env |
读取文件
1 | Regular env FS env |
可以看到的是,用户通过调用read,执行实际操作的是对应的设备文件,因为不同类型的文件对用户而言都是相同的(Fd),但是实际read却有区别。比如对管道文件的读和对普通文件的读肯定不一样。这种区别由不同的设备文件来体现。devfile_read把请求读取的文件的信息保存在fsipc中,通过ipc向Fs serv请求数据,fs serv一直在等待请求到来,在读到请求后,根据请求返还对应的文件内容,通过ipc的方式写回。
Spawning进程
spawning用于创建子进程,有点类似于Unix中的fork+exec过程,但是有点区别,因为我们的spawning过程运行在用户空间。
在fork和spawning中,父子进程需要共享文件描述符,之前的COW字段并不能满足要求,我们需要的是共享。
Spawning的流程如下:
- 打开文件,获取文件描述符Fd
- 读取ELF文件
- 调用fork创建子进程
- 设置child_tf,设置子进程eip为elf文件的入口点e_entry,设置esp为init_stack分配的栈空间
- 将ELF文件映射到子进程地址空间,并根据ELF来设置访问权限
- 拷贝共享的页
- 调用sys_env_set_trapframe()设置子进程的env_tf位child_tf。
- 调用 sys_env_set_status() 设置子进程为RUNNABLE状态。
pipe
pipe过程很简单,分配两个描述符,每个描述符会携带对应的数据区,将两个描述符的数据区映射到同一段物理内存,该段内存保存有r_offset、w_offset以及实际数据。也就是说pipe虽然和文件相关,但是并不涉及到实际的文件。